
Build a Small REST API in Go: A Practical 2026 Beginner’s Guide
Building a small REST API is one of the best ways to learn Go in a practical, production-minded way. You get exposure to the language’s core strengths—simple syntax, fast compilation, straightforward concurrency, and a standard library that can take you much further than many beginners expect. In 2026, Go remains a particularly strong choice for API services because it helps you keep the architecture lean without sacrificing reliability or maintainability.
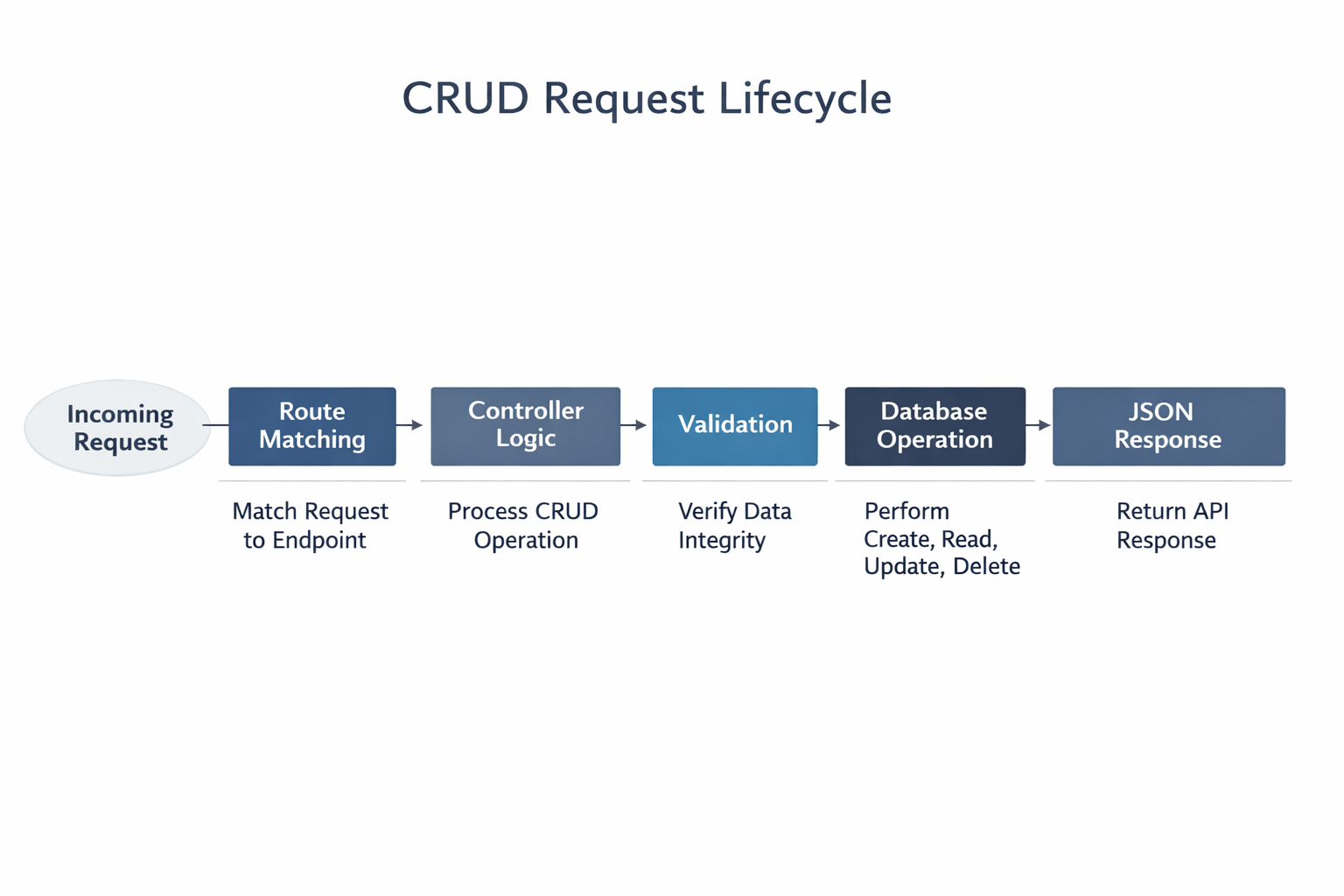
This guide walks through the complete lifecycle of a small REST API: choosing a stack, organizing a project, defining endpoints, implementing handlers, adding validation, choosing persistence, wiring middleware, writing tests, and hardening the service for real-world use. The focus is on clarity and pragmatism. You do not need a heavy framework or complex architecture to build something useful. In fact, for a beginner-friendly API, starting small often leads to better code and a better understanding of how the request/response cycle really works.
To keep the examples concrete, we will imagine a simple books API with CRUD operations. You can adapt the same patterns to tasks, notes, users, or any other resource. The goal is not just to copy code, but to understand the shape of a well-structured Go API so you can build your own services confidently.
1. Why Go for Small REST APIs
Go is a strong fit for small REST APIs because it balances simplicity, performance, and maintainability better than many languages that are either too abstract or too heavy for small services. The first practical advantage is fast startup and low overhead. Go binaries compile to a single executable, which makes deployment easy and predictable. For a REST API, that means you can move from source code to a runnable service without a long runtime dependency chain or a complicated packaging story.
The second advantage is concurrency. REST APIs often spend a lot of time waiting on I/O: database queries, cache lookups, external HTTP calls, message queues, and filesystem reads. Go’s goroutines and channels make it easy to handle concurrent requests and background work with a simple mental model. You do not need to introduce complex threading primitives just to coordinate lightweight tasks. The runtime handles the scheduling efficiently, which is helpful even in small APIs because it gives you room to grow without rewriting the service later.
The third major reason is the standard library. Go’s net/http, encoding/json, context, time, log, and testing packages are all good enough to build a respectable API with minimal dependencies. That means fewer moving parts, fewer upgrade headaches, and less framework lock-in. For beginners, this matters a lot. When the stack is minimal, you can actually see what the server is doing and why.
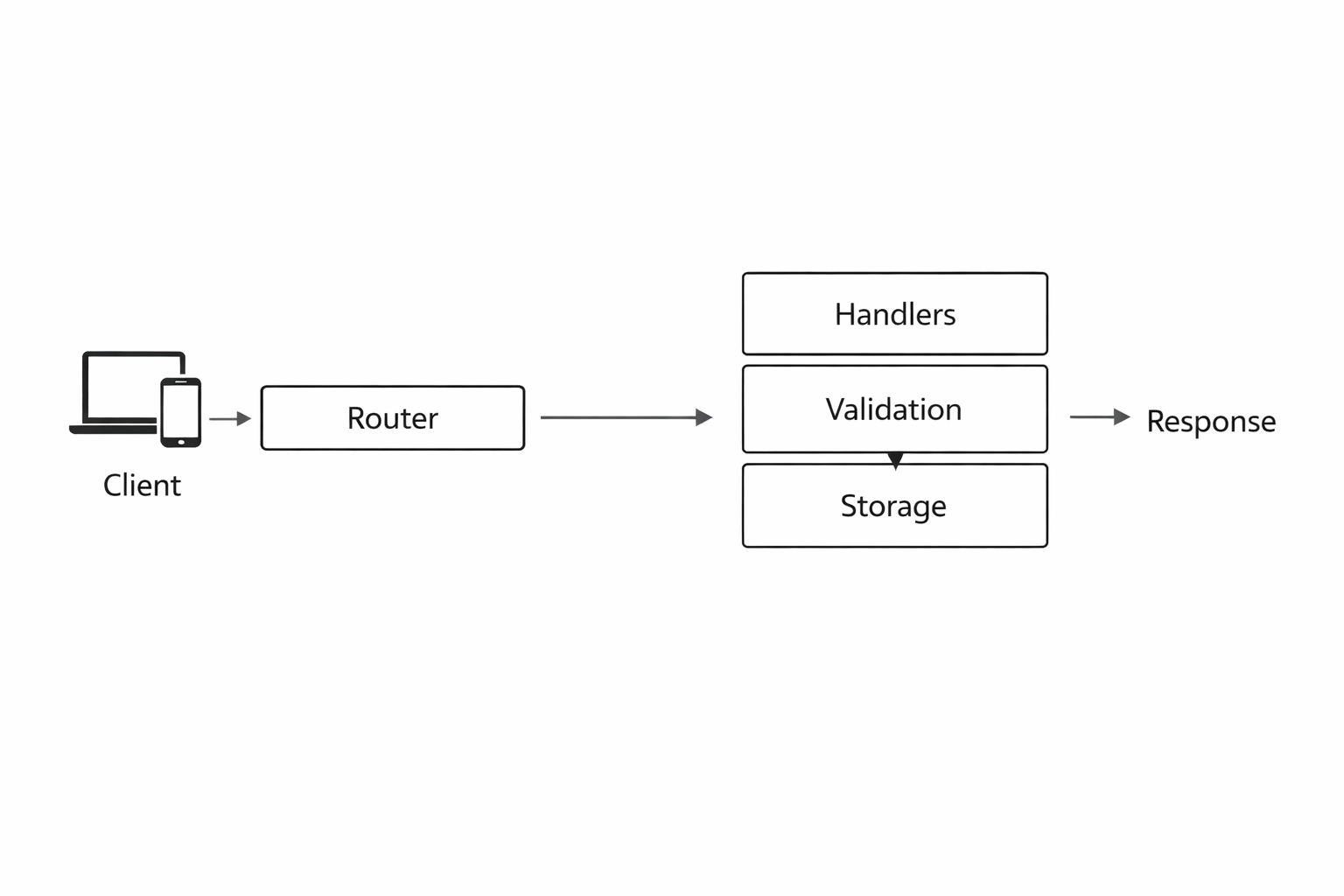
Finally, Go encourages a clean separation between data, behavior, and interfaces. That makes it easier to structure an API around handlers, services, and storage layers. You can start with a tiny implementation and later add validation, persistence, middleware, and observability without throwing everything away. For a small REST API, that combination of speed, clarity, and extensibility is hard to beat.
2. Choosing the Right Stack: net/http vs Gin vs Chi, and When to Keep It Minimal
When you build a Go REST API, the most important early decision is not which framework is “best,” but how much abstraction you actually need. For small APIs, the answer is often: less than you think. Go’s standard library net/http is fully capable of serving JSON endpoints, parsing request bodies, reading headers, managing timeouts, and returning status codes. If your API is simple, net/http is usually the best starting point because it teaches the fundamentals directly.
net/http is ideal when you want full control, minimal dependencies, and a deep understanding of the request lifecycle. You define your own routes, write handlers, and manage JSON encoding manually. This is not a downside for a small service. In fact, it often leads to better code because you are forced to be explicit about behavior.
Gin is a popular framework that adds conveniences such as routing helpers, middleware support, binding, and validation integrations. It can speed up development when you want a more opinionated API style or when your team already knows it well. Chi sits in the middle: it is lightweight, idiomatic, and focused on composable routing and middleware. Chi tends to be a strong choice when you want cleaner routing than raw net/http but do not want a heavyweight framework.
A useful rule of thumb is this: if your API has only a handful of endpoints, start with net/http or Chi. If you know you will need lots of middleware, route grouping, and binding helpers immediately, Gin may save time. But if you are learning or building a small service, resist the urge to add a framework just because it is popular.
Keeping it minimal has real benefits. Smaller dependency graphs are easier to secure, test, and update. Your code becomes more portable because the core logic is not tied to a large abstraction layer. And when you understand how to build the API without framework magic, you will be much better equipped to use a framework intentionally later.
3. Project Setup: Module Initialization, Folder Structure, Dependencies, and Configuration
A clean project setup prevents your API from turning into a tangle of handlers, models, and storage code. Start by initializing a Go module. This gives your project a proper import path and makes dependency management reproducible.
A practical setup begins like this:
mkdir books-api
cd books-api
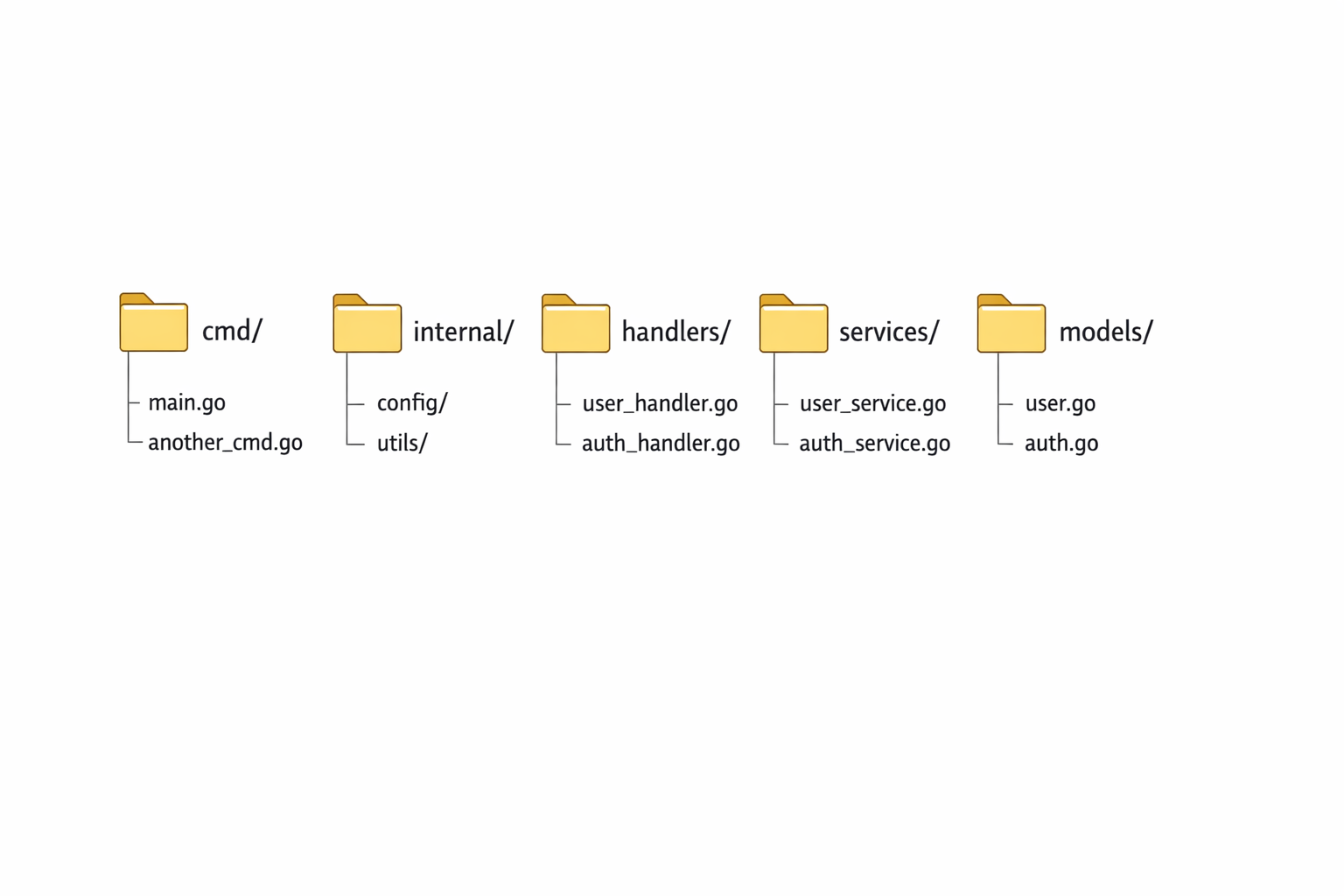
go mod init example.com/books-apiFrom there, define a folder structure that separates concerns without overengineering. For a small API, something like this works well:
books-api/
├── cmd/
│ └── api/
│ └── main.go
├── internal/
│ ├── handlers/
│ ├── models/
│ ├── store/
│ ├── middleware/
│ └── config/
├── test/
├── go.mod
└── go.sumThe cmd/api package holds the executable entry point. The internal directory contains application code that should not be imported from outside the module. This structure is a strong default because it keeps the boundary between reusable logic and executable code clean. For a beginner, it also makes the project easier to navigate.
Dependencies should be added carefully. If you can implement routing with net/http, you may not need anything else at all. If you prefer Chi or Gin, add only what you need for routing and middleware. Avoid pulling in validation, logging, and configuration libraries before you know you need them. Minimal dependencies reduce build complexity and keep the project easier to understand.
Configuration should be explicit and environment-driven. Typical values include:
PORTENVREAD_TIMEOUTWRITE_TIMEOUTIDLE_TIMEOUTDATABASE_URLor storage pathLOG_LEVEL
You can read them using os.Getenv or a tiny configuration package. For small services, a simple struct loaded from environment variables is enough. The key is consistency. Your app should be able to run locally, in a container, and in production with the same executable, changing only environment-specific values.
4. Designing the API: Resources, Endpoints, HTTP Methods, Status Codes, and Request/Response Models
Good API design starts with the resource model. For a beginner project, choose something simple and concrete, such as books. A resource-oriented API is easier to reason about than a collection of ad hoc actions because each endpoint maps to a clear entity and a predictable set of operations.
A typical CRUD API might look like this:
GET /books— list all booksGET /books/{id}— fetch one bookPOST /books— create a bookPUT /books/{id}— replace a bookPATCH /books/{id}— partially update a bookDELETE /books/{id}— remove a book
Use HTTP methods according to their meaning. GET should be safe and idempotent. POST is for creating new resources. PUT usually means replace the full resource. PATCH is for partial updates. DELETE removes the resource. If you follow these semantics consistently, your API becomes easier to use and debug.
Status codes matter just as much as routes. Some common responses are:
200 OKfor successful reads or updates201 Createdfor new resources204 No Contentfor successful deletes400 Bad Requestfor malformed input404 Not Foundwhen a resource does not exist409 Conflictfor duplicate or conflicting state422 Unprocessable Entitywhen input is syntactically valid but semantically wrong500 Internal Server Errorfor unexpected failures
Define request and response models separately from your internal storage representation when possible. That gives you flexibility to change persistence later without breaking the API contract. For example, a book request may include title, author, and year, while the response also includes id and created_at.
Example model:
type Book struct {
ID string `json:"id"`
Title string `json:"title"`
Author string `json:"author"`
Year int `json:"year"`
CreatedAt time.Time `json:"created_at"`
}For create and update requests, it is often better to define separate input structs:
type CreateBookRequest struct {
Title string `json:"title"`
Author string `json:"author"`
Year int `json:"year"`
}This keeps your API contract explicit and avoids accidental exposure of fields that should be server-controlled.
5. Implementing Routing and Handlers: Building CRUD Endpoints and Organizing Code Cleanly
Routing in Go can be very simple, especially if you start with net/http. A handler is just a function that receives a response writer and a request. That simplicity is powerful because it keeps your application logic easy to follow.
A minimal server setup might look like this:
package main
import (
"log"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("GET /books", listBooks)
mux.HandleFunc("POST /books", createBook)
mux.HandleFunc("GET /books/{id}", getBook)
mux.HandleFunc("PUT /books/{id}", updateBook)
mux.HandleFunc("DELETE /books/{id}", deleteBook)
server := &http.Server{
Addr: ":8080",
Handler: mux,
}
log.Println("server listening on :8080")
log.Fatal(server.ListenAndServe())
}Inside handlers, keep the responsibilities narrow. A handler should parse input, call application logic, and write a response. It should not contain storage-specific assumptions if you can avoid it. That makes testing easier and keeps your code cleaner.
Here is a simple example of a create handler:
func createBook(w http.ResponseWriter, r *http.Request) {
var req CreateBookRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
writeJSONError(w, http.StatusBadRequest, "invalid JSON body")
return
}
book := Book{
ID: "generated-id",
Title: req.Title,
Author: req.Author,
Year: req.Year,
CreatedAt: time.Now().UTC(),
}
writeJSON(w, http.StatusCreated, book)
}A useful pattern is to introduce a service layer between handlers and storage. The handler handles HTTP concerns; the service handles business rules; the store handles persistence. Even for a small API, this separation pays off because it prevents your handlers from becoming untestable blobs.
For example:
handlersparse requests and format responsesservicevalidates business logic and coordinates operationsstorereads/writes data
This structure gives you clean code without requiring an enterprise architecture. It is just enough abstraction to keep growth manageable.
6. Validation, Binding, and Error Handling: Input Checks, Consistent JSON Errors, and Edge Cases
Validation is where many beginner APIs become fragile. If you do not check inputs carefully, bad requests can quietly create bad data. The goal is to make validation predictable, consistent, and easy to extend.
Start with basic binding and parsing. When decoding JSON, always handle malformed input. Prefer decoding from the request body into a specific struct rather than into a generic map. This gives you type safety and clearer validation.
Then validate field-level rules. For a CreateBookRequest, you might require:
Titlecannot be emptyAuthorcannot be emptyYearmust be in a valid range
Example validation:
func (r CreateBookRequest) Validate() error {
if strings.TrimSpace(r.Title) == "" {
return errors.New("title is required")
}
if strings.TrimSpace(r.Author) == "" {
return errors.New("author is required")
}
if r.Year < 1450 || r.Year > time.Now().Year()+1 {
return errors.New("year is out of range")
}
return nil
}You should also return consistent error responses. A common mistake is to send plain text sometimes, JSON other times, and different error shapes across handlers. That makes clients harder to write. Instead, define one error format:
{
"error": {
"message": "title is required"
}
}For more advanced APIs, you can include field-level details:
{
"error": {
"message": "validation failed",
"fields": {
"title": "required",
"year": "must be between 1450 and 2027"
}
}
}Edge cases deserve attention too. Handle:
invalid or missing resource IDs
empty request bodies
unknown fields if you want strict input
duplicate creates
delete requests for missing records
partially valid
PATCHpayloads
One useful defensive technique is to limit request body size with http.MaxBytesReader. That prevents clients from sending huge payloads that waste memory or cause denial-of-service issues.
Good error handling is not just about user experience. It is also about observability and supportability. If every failure has a clear shape and a useful message, debugging becomes much faster.
7. Persistence Options: In-Memory Storage, Files, or a Lightweight Database Layer
A small REST API does not need a full database on day one, but it does need a persistence strategy. The right choice depends on whether you are learning, prototyping, or preparing for real usage.
The simplest option is in-memory storage. This is perfect for learning and tests because it removes external dependencies. A map protected by a mutex is enough for a small project:
type MemoryStore struct {
mu sync.RWMutex
items map[string]Book
}In-memory storage is fast and easy, but it is ephemeral. Restart the process and your data disappears. That makes it unsuitable for most production use cases, but excellent for early development.
File-based persistence is the next step up. You can serialize data to JSON or another format and load it at startup. This works well for tiny tools and local applications, but it becomes harder to manage as concurrency increases. You need to think about atomic writes, file corruption, and locking. Still, for a very small API, it may be a practical middle ground.
A lightweight database layer is often the best long-term answer. SQLite is a strong choice for small APIs because it is simple, embedded, and easy to deploy. You can keep the operational footprint small while gaining durability and SQL querying. For a beginner service, SQLite often provides the best balance of simplicity and real-world usefulness.
If you expect growth or multi-instance deployment, you may later move to PostgreSQL or another server database. The key is to abstract persistence behind an interface so the rest of your application does not care whether data comes from memory, files, or SQL. That gives you room to evolve without redesigning the whole codebase.
A small interface might look like this:
type BookStore interface {
Create(ctx context.Context, book Book) error
Get(ctx context.Context, id string) (Book, error)
List(ctx context.Context) ([]Book, error)
Update(ctx context.Context, book Book) error
Delete(ctx context.Context, id string) error
}This kind of boundary is one of the most useful habits you can develop early.
8. Middleware Essentials: Logging, Recovery, CORS, Timeouts, and Request Tracing
Middleware is where an API becomes operationally usable. Even a tiny service benefits from a few essential cross-cutting concerns.
Logging should be one of the first middleware layers you add. At minimum, log the request method, path, status code, and duration. Structured logging is even better because it makes logs easier to search and analyze. For beginners, a simple logger is enough if it is consistent.
Recovery middleware is important because it prevents a single panic from crashing your entire process. In net/http, a panic in one handler can bring down the server if not recovered. Recovery middleware should catch panics, log the stack trace, and return a 500 response.
CORS matters if your API will be called from a browser-based frontend. Configure it intentionally rather than opening everything by default. Limit allowed origins, methods, and headers to what you actually need.
Timeouts are critical for protecting your server. Set ReadTimeout, WriteTimeout, and IdleTimeout on the HTTP server. Without them, slow or malicious clients can tie up resources longer than necessary. You should also pass context.Context through your handlers and service methods so work can be canceled when the request is canceled.
Request tracing is increasingly useful even in small services. A simple request ID middleware can attach an identifier to each incoming request and return it in the response header. That makes it much easier to correlate logs across layers. If you later adopt OpenTelemetry or another observability stack, you will already have the conceptual structure in place.
A good middleware chain for a small API often includes:
request ID assignment
request logging
panic recovery
CORS
timeout enforcement
You do not need every middleware from day one. But you should treat logging, recovery, and timeouts as baseline essentials, not optional extras.
9. Testing the API: Unit Tests, Handler Tests, Table-Driven Tests, and Integration Checks
Testing is where a small API gains confidence. In Go, tests are straightforward to write and easy to organize, which makes them a natural part of the development workflow.
Start with unit tests for your pure logic. Validation functions, ID generation, transformation functions, and service rules are all good candidates. These tests should be fast and isolated from HTTP and persistence.
Next, write handler tests. In Go, you can use net/http/httptest to simulate requests and inspect responses without running a real server. This is ideal for checking status codes, JSON bodies, headers, and routing behavior.
A handler test often looks like this:
func TestCreateBookHandler(t *testing.T) {
body := strings.NewReader(`{"title":"Dune","author":"Frank Herbert","year":1965}`)
req := httptest.NewRequest(http.MethodPost, "/books", body)
rr := httptest.NewRecorder()
handler := http.HandlerFunc(createBook)
handler.ServeHTTP(rr, req)
if rr.Code != http.StatusCreated {
t.Fatalf("expected status %d, got %d", http.StatusCreated, rr.Code)
}
}Table-driven tests are a great Go pattern because they reduce repetition and make edge cases explicit. For validation, you might test multiple inputs in one function:
func TestValidateCreateBookRequest(t *testing.T) {
tests := []struct {
name string
input CreateBookRequest
wantErr bool
}{
{"valid request", CreateBookRequest{Title: "Dune", Author: "Frank Herbert", Year: 1965}, false},
{"missing title", CreateBookRequest{Author: "Frank Herbert", Year: 1965}, true},
{"bad year", CreateBookRequest{Title: "Dune", Author: "Frank Herbert", Year: 1200}, true},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
err := tt.input.Validate()
if (err != nil) != tt.wantErr {
t.Fatalf("got err=%v, wantErr=%v", err, tt.wantErr)
}
})
}
}Integration checks are the final layer. These tests exercise multiple components together, such as handlers plus storage or handlers plus a real database. They are slower than unit tests, so use them selectively. Even a few integration tests can catch issues that unit tests miss, especially around JSON serialization, persistence, and request flow.
A healthy test strategy usually looks like this:
many unit tests
several handler tests
a smaller number of integration tests
That combination gives you speed during development and confidence before deployment.
10. Hardening and Next Steps: Performance, Security, Documentation, Deployment, and Versioning
Once your API works, the next step is making it robust. Hardening is not about adding complexity for its own sake. It is about protecting the service from predictable failure modes and making it easier to operate.
Performance starts with measuring rather than guessing. For a small API, the biggest wins usually come from efficient JSON handling, sensible timeouts, reduced allocations, and choosing an appropriate persistence layer. You do not need premature micro-optimization. Focus on the hot paths first: request parsing, storage access, and response encoding.
Security is equally important. At a minimum:
validate all input
avoid leaking internal errors to clients
limit request sizes
use timeouts
configure CORS carefully
sanitize logs if they may contain sensitive data
If your API handles authentication later, use a well-defined scheme such as API keys, JWTs, or session-based auth depending on the use case. Also remember that security is operational, not just code-level. Secure secrets management, proper environment configuration, and least-privilege deployment all matter.
Documentation should be written early, not after the code is “done.” Even a small API benefits from a README that explains endpoints, payloads, environment variables, and local startup steps. If your API grows, OpenAPI documentation becomes very useful because it gives clients a machine-readable contract.
Deployment should stay boring. A single Go binary is easy to containerize and ship. Keep health checks simple. Make startup deterministic. Ensure your server can shut down gracefully by listening for termination signals and allowing in-flight requests to finish before exit.
Versioning matters once clients depend on your API. A common approach is to put versions in the path, such as /v1/books. That makes it easier to introduce breaking changes later without disrupting existing clients. Even if your first version is tiny, thinking about versioning early helps you avoid painful migrations later.
Conclusion
A small REST API in Go is one of the most practical projects you can build as a beginner or intermediate developer. Go’s standard library, concurrency model, and deployment simplicity make it a particularly good choice for services that need to stay lean and reliable. The real value of the exercise is not just learning syntax; it is learning how to design clear endpoints, separate responsibilities, validate input, manage persistence, and write tests that give you confidence.
The best approach is usually to start minimal. Use net/http or a light router, define a clean resource model, keep handlers focused, and add only the pieces you need: validation, storage, middleware, and tests. As the API grows, the structure you establish early will make it much easier to evolve the code without losing clarity.
If you apply the patterns in this guide, you will end up with more than a demo. You will have the foundation for a maintainable Go service that is easy to understand, easy to test, and ready to grow.