
RAG Basics Explained: When Retrieval-Augmented Generation Works and When It Fails
Retrieval-augmented generation, or RAG, has become one of the most practical patterns in modern AI application design. It bridges two worlds that do not naturally solve the same problem well: large language models, which are excellent at fluent language generation and general reasoning, and retrieval systems, which are excellent at finding the right information from a large corpus. In practice, this combination lets teams build assistants that answer questions from proprietary documents, support dynamic knowledge bases, and reduce dependence on model memory alone.
RAG matters because most real-world applications are not static. Policies change, product documentation evolves, support articles are revised, and internal knowledge expands continuously. Fine-tuning a model on this content is often expensive, slow, and brittle. RAG offers a more flexible alternative: keep the model general-purpose, and inject the right context at inference time. That makes it a strong default for many enterprise and product use cases.
But RAG is not magic. It can fail in predictable ways: retrieval can miss the right evidence, chunking can damage meaning, context can become noisy, and the model can still hallucinate even when given relevant documents. As systems grow more complex, it also becomes clear that RAG is not the best fit for every task. Some problems need stronger reasoning, multi-step planning, or tool use rather than document lookup.

This post breaks down how RAG works, where it shines, where it breaks down, and how to decide whether it is the right architecture for your AI product.
1. What Retrieval-Augmented Generation Is and Why It Matters for Modern AI Apps
Retrieval-augmented generation is an architecture that combines a retrieval layer with a generative model. Instead of asking the model to answer solely from its parameters, the system first retrieves relevant passages from an external knowledge source and then provides those passages as context to the model. The model then generates an answer grounded in that retrieved evidence.
This matters because language models are not databases. They are not inherently reliable stores of factual, up-to-date, or organization-specific information. Even highly capable models may produce confident but incorrect responses when asked about recent policy changes, niche internal procedures, or proprietary product behavior. RAG addresses that limitation by making the answer depend, at least partially, on the retrieved source material.
For modern AI apps, the value proposition is straightforward. RAG can reduce hallucinations, improve transparency, and enable rapid updates without retraining the model. If a company updates a policy document, the retrieval index can be refreshed much faster than a model can be fine-tuned. If a support assistant needs to answer from thousands of product manuals, RAG gives it a path to relevant evidence without stuffing the entire knowledge base into the prompt.
RAG also helps with governance. Teams can control what data is searchable, what sources are allowed, and which documents should be excluded. This is especially useful in regulated environments, internal enterprise assistants, and customer-facing systems where provenance matters. When designed well, RAG allows the product to say not only “here is the answer,” but also “here is where the answer came from.”
The key insight is that RAG shifts AI from memorization toward evidence-based generation. That shift is what makes it so important for modern applications, especially those that operate in dynamic, domain-specific, or enterprise knowledge settings.
2. The Core RAG Pipeline: Chunking, Indexing, Retrieval, Reranking, and Generation
A RAG system is usually built as a pipeline, and each stage affects quality. The most common sequence is: ingest documents, chunk them, create embeddings or inverted indexes, retrieve candidate passages, rerank them, and pass the selected context to a generator.
Chunking
Chunking is the process of splitting source documents into smaller units. This is necessary because most models have context limits and retrieval works better over manageable segments. But chunking is also one of the most important design choices. If chunks are too small, they may lose context and become semantically incomplete. If they are too large, retrieval becomes less precise and the prompt gets bloated with irrelevant text.
A good chunking strategy usually preserves semantic boundaries. For example, a policy document might be chunked by section headings, while a technical manual might be chunked by subsection or function description. Many teams also add overlap between chunks to avoid cutting key ideas in half.
Indexing
Once documents are chunked, they are indexed for retrieval. In vector-based RAG, each chunk is converted into an embedding and stored in a vector database. In lexical search, the text is indexed for keyword matching using algorithms like BM25. Many modern systems use both.
Indexing is not just storage. It determines how the system later finds evidence. Vector search is strong for semantic similarity, while lexical search is strong for exact terms, identifiers, codes, and proper nouns. A strong index often combines these strategies.
Retrieval
Retrieval is the act of finding candidate chunks that match the query. The system may search by embedding similarity, keyword overlap, metadata constraints, or a hybrid strategy. Retrieval quality is usually measured by whether the correct evidence appears in the candidate set, not whether the final answer is good yet.
Reranking
Reranking is often the difference between a decent system and a strong one. The retriever may return 20 or 50 candidate chunks, but not all are equally useful. A reranker scores them more carefully, often using a cross-encoder or another relevance model. This step helps surface the best evidence and suppress distractors.
Generation
Finally, the selected chunks are inserted into the prompt and the language model generates the answer. At this stage, prompt design matters. The model should be instructed to use only the provided context when appropriate, cite sources if needed, and admit uncertainty when evidence is missing.
A robust RAG system is therefore not a single model call. It is an engineered pipeline where each component can improve or degrade the final result. Weak chunking can hurt retrieval. Weak retrieval can hurt generation. Weak prompt design can turn good evidence into vague answers.
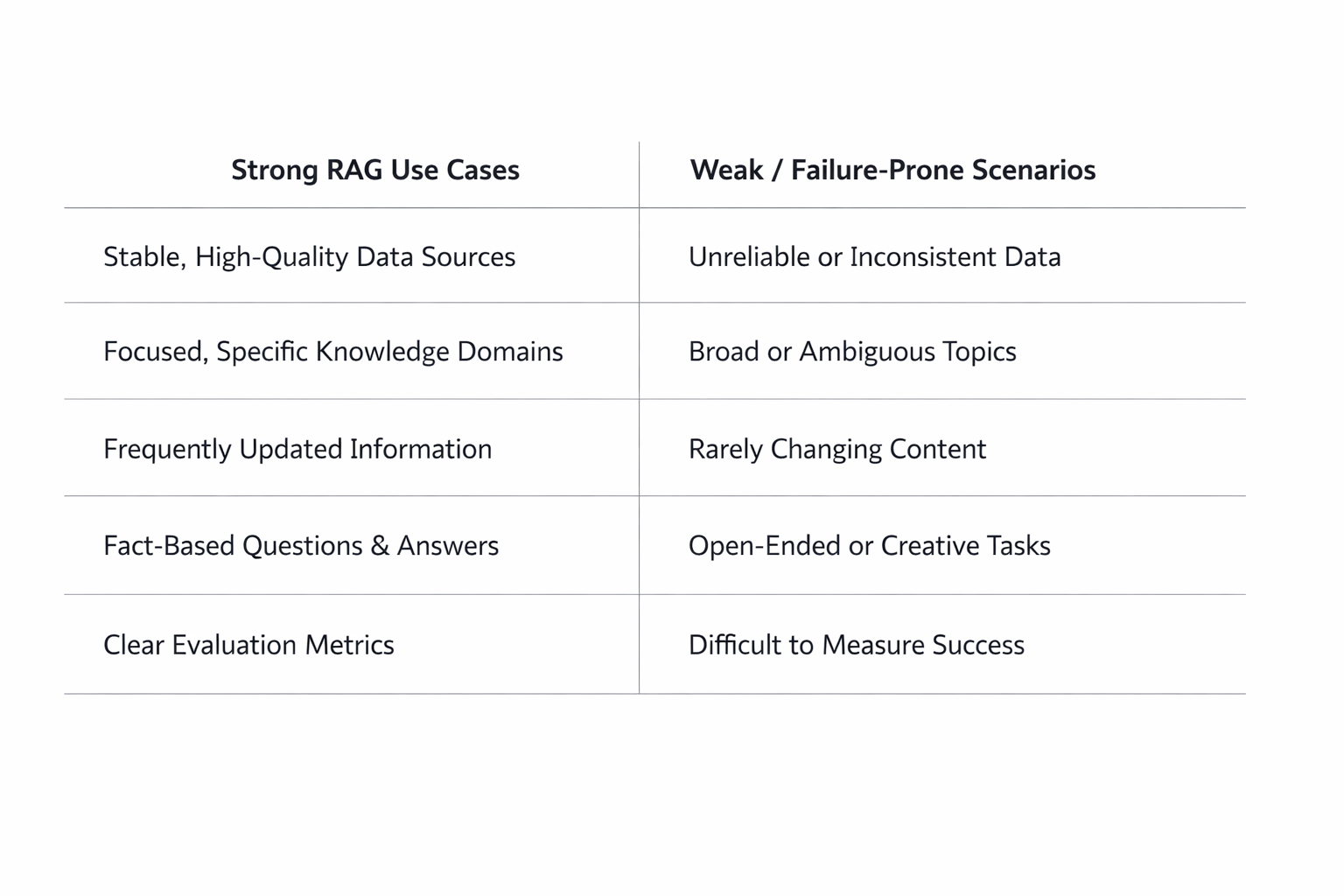
3. Where RAG Works Best: Grounded Q&A, Frequently Updated Knowledge, and Domain-Specific Assistants
RAG is especially effective when the task is to answer questions grounded in a defined corpus. That includes support agents, internal knowledge assistants, documentation chatbots, compliance helpers, and research tools that need to pull from a curated set of sources. In these scenarios, the main challenge is not creativity; it is finding the right evidence quickly and accurately.
Grounded Q&A
If users ask factual questions like “What does the company travel policy say about international reimbursement?” or “How do I configure feature X in version Y?” RAG is a strong fit. The answer should be anchored in specific documents, and the system can retrieve exactly those documents before responding. This is one of the clearest use cases because the answer can be validated against sources.
Frequently updated knowledge
RAG shines when information changes often. Product documentation, policy manuals, legal summaries, medical guidance, and market intelligence are all examples where the underlying knowledge shifts frequently enough that retraining would be too slow. With RAG, updating the corpus and reindexing it is usually sufficient to keep answers current.
Domain-specific assistants
RAG is also valuable in narrow domains where terminology matters. Engineering assistants, legal research tools, finance copilots, and clinical knowledge systems benefit from retrieval because they need access to specialized language and authoritative sources. In these settings, a general model alone may understand the vocabulary but not the specific operational rules or latest internal guidance.
The strongest RAG applications usually have three traits: a clear source corpus, a predictable question style, and a need for freshness or provenance. If the answer can be found in documents and the user cares about traceability, RAG is usually worth considering.
4. Latest Trends in RAG Research and Practice: Agentic RAG, Multimodal RAG, Graph RAG, and Stronger Benchmarks
RAG has evolved quickly beyond the basic “retrieve top-k chunks and stuff them into a prompt” pattern. Several newer directions are reshaping how practitioners think about retrieval and grounding.
Agentic RAG
Agentic RAG introduces multi-step behavior. Instead of performing one retrieval pass, the system can plan, refine the query, retrieve again, inspect intermediate results, and decide whether more evidence is needed. This is useful for ambiguous questions or tasks that require progressive narrowing. Rather than treating retrieval as a one-shot operation, agentic RAG treats it as a loop.
Multimodal RAG
Not all knowledge is textual. Multimodal RAG extends retrieval to images, diagrams, tables, audio, and video frames. This matters for technical documentation, manufacturing, medicine, and design workflows where important information is often embedded in non-text artifacts. A multimodal assistant may need to answer questions by retrieving both a paragraph and a diagram.
Graph RAG
Graph RAG adds structure by representing entities, relationships, and dependencies as a graph. This can improve retrieval when questions involve connected facts, organizational relationships, or multi-hop reasoning over structured knowledge. Graph-based approaches are especially attractive when documents are dense with entities and cross-references.
Stronger benchmarks
The research community has also moved toward better evaluation. Early RAG systems were often judged by whether the final answer sounded good. That is not enough. Today there is more focus on benchmarks that separately measure retrieval quality, grounding, faithfulness, and end-to-end task success. This is important because a model can produce a polished answer while ignoring the retrieved evidence, and a retriever can find relevant text while the generator still fails to use it properly.

The trend line is clear: RAG is becoming more agentic, more multimodal, more structured, and more rigorously evaluated. Teams adopting RAG today should expect the architecture to be more than a simple search-and-answer loop.
5. Key Success Factors: High-Quality Content, Good Chunking Strategy, Hybrid Search, and Context-Aware Retrieval
RAG success is often less about model size and more about information quality and retrieval design. The best systems usually share a few common characteristics.
High-quality content
If the underlying corpus is incomplete, outdated, duplicated, or poorly written, RAG cannot fully compensate. Retrieval can only surface what exists. Garbage in, garbage out still applies. Strong source hygiene matters: remove obsolete versions, deduplicate content, and prefer canonical documents over random copies.
Good chunking strategy
Chunking should preserve meaning. A technical specification may require section-aware splitting. A legal policy may require paragraph-level integrity. A support article may benefit from chunks aligned with headings and procedural steps. The right strategy depends on how people ask questions and how the source documents are structured.
Hybrid search
Hybrid search combines lexical and semantic retrieval. This is powerful because many user queries include exact terms, product names, IDs, code symbols, or unique phrases that embeddings alone may miss. At the same time, semantic search helps when users ask in natural language or paraphrase the source. Hybrid retrieval often delivers better recall than either method alone.
Context-aware retrieval
Context-aware retrieval uses signals beyond the raw query. These signals can include the user’s role, the current page or task, metadata tags, document recency, access permissions, and conversation history. For example, a support assistant might prioritize documents relevant to the product version the user is discussing. A company assistant might filter by department, region, or policy scope.
In practice, high-performing RAG systems are designed around relevance engineering. They do not just retrieve “similar text.” They retrieve the right text for this user, in this context, for this task.
6. Common Failure Modes: Poor Retrieval Recall, Noisy Context, Hallucinations, Prompt Injection, and Stale or Incomplete Corpora
RAG often fails in ways that look like model issues but actually begin earlier in the pipeline.
Poor retrieval recall
If the retriever never finds the correct document, the generator cannot answer correctly. This is one of the most common failure modes. Recall problems can come from weak embeddings, poor chunking, bad query formulation, or an index that is too small or poorly filtered. The model may still produce an answer, but it will be based on irrelevant evidence or its own priors.
Noisy context
Even when retrieval finds relevant chunks, the prompt may include too much irrelevant text. Large context windows can create a false sense of safety, but more context is not always better. Irrelevant chunks distract the model, dilute the signal, and increase the chance of contradictions.
Hallucinations
A RAG system can still hallucinate. The presence of source text does not guarantee faithful use of that text. The model may blend retrieved evidence with prior knowledge, infer unsupported details, or answer too confidently when the context is incomplete. Grounding helps, but it does not eliminate generation risk.
Prompt injection
If the retrieved corpus includes untrusted content, malicious instructions can be embedded in source documents. A model that naïvely follows retrieved text can be tricked into ignoring system rules, leaking data, or producing unsafe output. This is a real security concern in document-heavy applications, especially where users can upload content into the same retrieval pool.
Stale or incomplete corpora
RAG can only answer from what it has access to. If the corpus is missing recent updates, partial in coverage, or inconsistent across sources, the system may return confidently outdated answers. This is especially dangerous because the assistant may appear well grounded while actually citing obsolete information.
These failure modes often interact. Poor recall leads to noisy fallback evidence. Noisy context increases hallucination risk. Stale documents reduce trust. Prompt injection turns a knowledge base into a potential attack surface. Effective RAG engineering has to treat all of these as first-class concerns.
7. Why RAG Struggles on Complex Reasoning, Long-Horizon Tasks, and Questions Requiring Synthesis Across Many Documents
RAG is strongest when the answer exists in one or a few relevant passages. It becomes weaker when the task requires deep reasoning across many sources, multiple intermediate steps, or long-term planning.
Complex reasoning
If a question requires arithmetic, causal analysis, constraint solving, or layered inference, retrieval alone is not enough. Retrieved documents may provide facts, but the system still has to reason correctly over them. That is where models can make subtle mistakes, especially if the prompt is crowded or the evidence is ambiguous.
Long-horizon tasks
Tasks like project planning, litigation analysis, research synthesis, or strategic decision support often require maintaining state across many steps and revisiting earlier conclusions. RAG systems built around single-turn question answering are not naturally suited to this. They can retrieve evidence, but they do not inherently manage workflow, checkpoints, or iterative refinement.
Cross-document synthesis
Questions that span many documents are especially hard. A user might ask for a comparison across policies, a trend analysis over multiple reports, or a summary of conflicting viewpoints. In these cases, retrieval may return fragments, but the hard part is synthesizing them into a coherent answer without losing nuance. Basic RAG often underperforms because it lacks a strong mechanism for aggregating evidence across sources.
A useful mental model is this: RAG is an evidence-fetching system, not a full reasoning architecture. It can support reasoning, but it does not guarantee it. When the task needs planning, multi-hop logic, or stateful execution, teams often need to add orchestration, tools, or agentic loops.
8. How to Evaluate RAG Systems: Retrieval Metrics, Faithfulness, Answer Relevance, and End-to-End Task Performance
Evaluating RAG requires measuring more than one thing. A system can retrieve good evidence but generate a poor answer, or generate a decent answer from weak evidence, which makes diagnosis difficult unless you separate the layers.
Retrieval metrics
Retrieval should be evaluated with metrics like recall at k, precision at k, and mean reciprocal rank. These help answer questions such as: Did the correct document appear in the top results? Was the relevant passage ranked high enough to matter? Retrieval metrics are essential because many downstream failures begin here.
Faithfulness
Faithfulness measures whether the answer is supported by the retrieved evidence. This is one of the most important RAG-specific quality dimensions. A response may be fluent and useful-looking but still include unsupported claims. Faithfulness evaluation can be done manually, with model-based judges, or with structured checks against source text.
Answer relevance
Even a faithful answer can miss the point if it does not answer the user’s actual question. Answer relevance evaluates whether the generated response addresses the intent, not just the source material. This is especially important when users ask nuanced or multi-part questions.
End-to-end task performance
Ultimately, the system should be measured on whether it helps users accomplish the task. In a support setting, that might mean resolution rate. In a knowledge assistant, it might mean time saved or fewer escalations. In a research workflow, it might mean better summaries or faster discovery. End-to-end evaluation matters because retrieval and generation metrics do not always predict real utility.
A mature evaluation stack usually includes offline benchmarks, human review, and live product metrics. The best teams also inspect failure cases by layer: retrieval misses, reranking mistakes, prompt failures, and generation errors. That kind of decomposition is what makes RAG systems actually improve over time.
9. Design Patterns That Improve Outcomes: Query Rewriting, Reranking, Citations, Metadata Filters, and Fallback Workflows
Good RAG systems are rarely built from a single retrieval call. They use layered design patterns that increase recall, improve precision, and make failures safer.
Query rewriting
Users often ask vague, shorthand, or context-dependent questions. Query rewriting transforms the original question into a better retrieval query. For example, the system may expand abbreviations, resolve pronouns, or convert a conversational request into keyword-rich search terms. This improves retrieval quality without changing the user experience.
Reranking
As noted earlier, reranking is one of the highest-leverage improvements available. A first-stage retriever can prioritize broad recall, while a reranker can focus on precision. This two-stage setup is often much better than relying on nearest-neighbor search alone.
Citations
Citations improve trust and make verification easier. When an assistant can cite the source documents it used, users can inspect the evidence directly. Citations also create pressure for better grounding, because unsupported claims become easier to spot. In many enterprise settings, citations are not optional; they are part of the product’s value proposition.
Metadata filters
Metadata helps narrow the search space. Filters based on document type, version, region, department, access level, or recency can dramatically improve relevance. For example, a customer-facing support assistant should not retrieve internal engineering notes unless explicitly allowed.
Fallback workflows
No retrieval system is perfect. A good design includes fallback behavior when confidence is low. The assistant may ask a clarifying question, broaden the search, route to a human, or explain that it could not find enough evidence. This is better than producing a confident but unsupported answer.
These patterns matter because RAG quality is cumulative. A query rewrite can improve retrieval. Reranking can improve precision. Filters can improve safety. Citations can improve trust. Fallbacks can prevent bad answers from becoming user-visible incidents.
10. Decision Framework: When to Use RAG, When to Fine-Tune, and When to Move to Agentic or Tool-Based Architectures
The most important architectural question is not “Should we use RAG?” but “What kind of problem are we solving?”
Use RAG when:
The answer depends on external documents or changing knowledge.
You need grounding, provenance, or citations.
The corpus can be indexed and searched effectively.
Freshness matters more than model adaptation.
The task is mostly question answering, lookup, summarization, or document-backed assistance.
In these cases, RAG is usually the best first choice because it is fast to deploy, easy to update, and more transparent than pure generation.
Fine-tune when:
The task requires a consistent style, format, or behavior that retrieval alone cannot enforce.
You have stable training data and a narrow target behavior.
The model needs to learn patterns, not just access facts.
Latency or retrieval complexity is a concern and the knowledge base is not the main issue.
Fine-tuning is not a replacement for knowledge retrieval. It is better for behavior shaping than for dynamic factual updates.
Move to agentic or tool-based architectures when:
The task requires planning, iterative reasoning, or multi-step execution.
The system must interact with APIs, databases, calculators, schedulers, or external services.
The answer depends on actions, not just documents.
You need workflows that maintain state across multiple turns or tasks.
In these situations, RAG may still be part of the solution, but it is no longer sufficient by itself. An agentic or tool-based system can retrieve evidence, call tools, validate outputs, and decide what to do next. That is a better fit for operational tasks than a pure retrieve-and-generate loop.
The practical rule is simple: if the problem is “find and explain,” use RAG. If the problem is “learn a stable pattern,” consider fine-tuning. If the problem is “plan, act, and adapt,” move toward agents or tool orchestration.
Conclusion
RAG is one of the most useful architectures in applied AI because it connects language models to external knowledge in a controllable, updateable way. It works best when the answer is grounded in documents, the corpus is high quality, retrieval is well tuned, and the task is primarily about lookup or explanation. It fails when retrieval misses, context is noisy, corpora are stale, or the task demands deeper reasoning and synthesis than a simple retrieval loop can support.
The most effective RAG systems are not accidental. They are engineered with good chunking, hybrid search, reranking, metadata filters, citations, and fallback behavior. They are also evaluated carefully, with separate attention to retrieval quality, faithfulness, and real user outcomes.
If you think about RAG as an evidence pipeline rather than a magic answer engine, its strengths and limitations become much clearer. That perspective helps teams choose the right architecture, reduce failure rates, and build AI products that are actually useful in production.