
Choosing a Database in 2026: PostgreSQL vs MySQL vs MongoDB vs Redis
Choosing a database in 2026 is no longer a simple question of “SQL or NoSQL.” Modern systems have to balance transactional correctness, developer velocity, operational cost, query flexibility, latency, and AI-era use cases such as vector search, semantic caching, and real-time context. The best database is rarely the most popular one in the abstract; it is the one that fits your data model, your team, and your growth path.
That matters more than ever in 2026 because the database landscape has become both more mature and more specialized. PostgreSQL continues to expand as the default general-purpose choice for serious application backends. MySQL remains the pragmatic standard for stable, high-scale OLTP workloads and for teams that value predictability. MongoDB keeps winning on document-centric application design and rapid iteration. Redis has evolved far beyond “just a cache” into a real-time data layer for sessions, queues, ephemeral state, and low-latency features.
At the same time, the ecosystem has shifted. PostgreSQL has recent releases in the 18.x line, with 18.4 released on May 14, 2026. MySQL’s 8.4 LTS track is positioned explicitly for long-term stability, with maintenance releases continuing through 2026. MongoDB continues pushing into AI and production agent workflows. Redis has doubled down on real-time and GenAI-oriented features, with 8.6 and 8.8-era improvements surfacing in 2026. In other words, the decision is not just about storage; it is about platform direction. (postgresql.org)

1. Introduction: why database choice matters more than ever in 2026
In earlier eras, database choice often felt like a one-time infrastructure decision made by backend engineers. In 2026, it is a product decision, an operational decision, and increasingly an AI architecture decision. The database you choose affects how fast your team ships features, how safely you evolve schemas, how easily you scale reads and writes, and how expensive your infrastructure becomes as usage grows. It also shapes the kinds of features you can support without introducing extra systems.
The pressure is higher because modern applications are more heterogeneous. A single product might need durable transactions for billing, flexible document storage for product catalogs, fast lookups for sessions and rate limits, and vector-enabled retrieval for AI features. That does not necessarily mean you should use four databases everywhere, but it does mean that “best database” is rarely a universal answer. You need to choose deliberately.
Another reason this choice matters in 2026 is that cloud costs are more visible and less forgiving. A database that is technically excellent but expensive to run, hard to tune, or overkill for your workload can become a drag on the business. Conversely, a database that is cheap and easy today but awkward under growth can force painful migrations later. The most successful teams optimize for the smallest system that still satisfies correctness and scale requirements.
The final reason is ecosystem maturity. In 2026, the leading databases are not simply storage engines; they are opinionated platforms with replication, backup tooling, observability integrations, managed-service offerings, and sometimes built-in vector or real-time features. That gives teams more leverage, but it also increases lock-in and the cost of bad assumptions. Database choice now deserves the same rigor as language or cloud-provider selection.
2. The current landscape: popularity trends, rankings, and what the data says
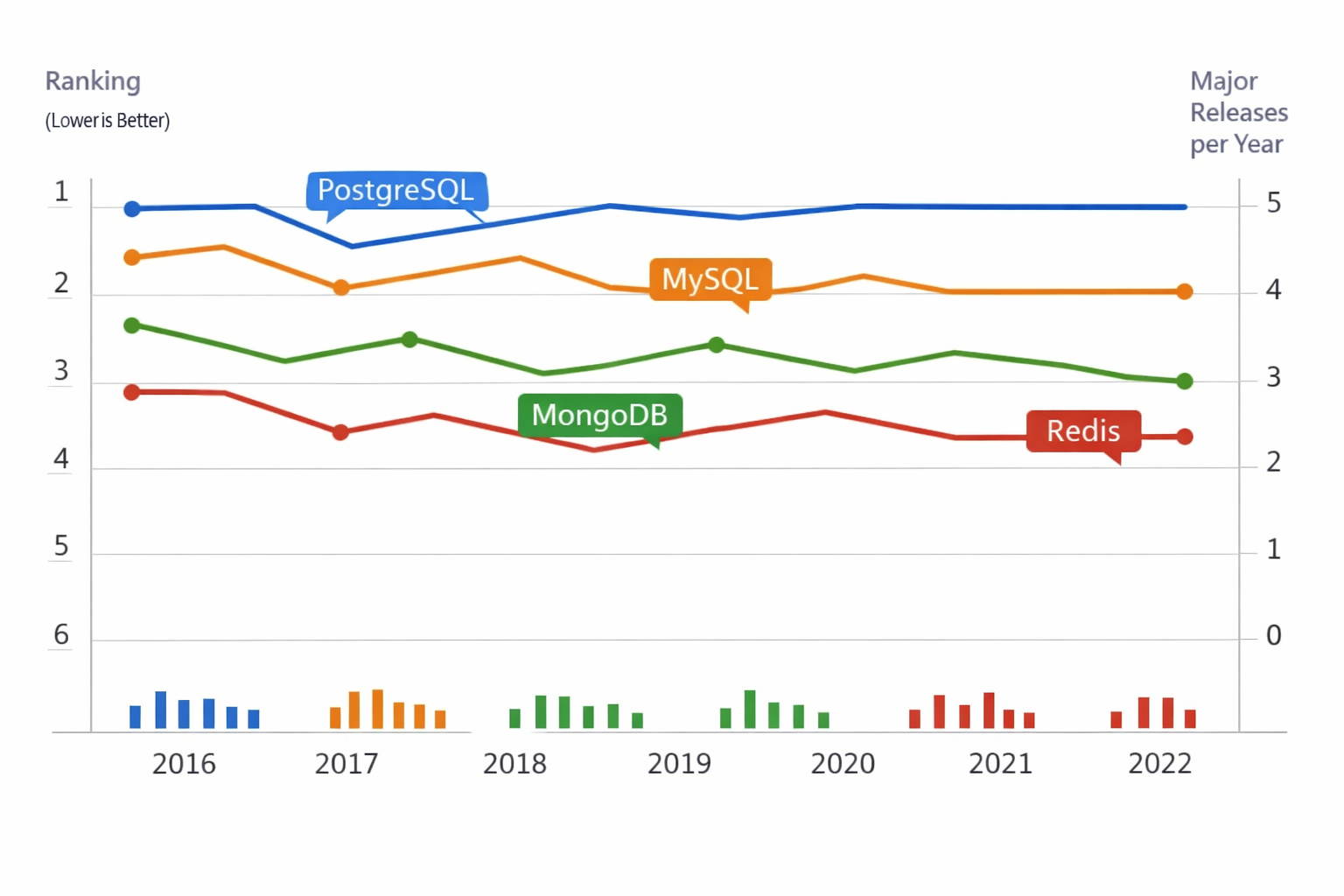
If you look at popularity rankings, the same names continue to dominate the top of the market: PostgreSQL, MySQL, MongoDB, and Redis remain among the most widely used systems. DB-Engines’ March 2026 ranking still places these systems prominently, reflecting their long-term relevance rather than short-lived trend status. That persistence is important. It suggests each database has found a durable niche instead of being displaced by newer entrants. (db-engines.com)
But popularity should not be confused with suitability. PostgreSQL tends to score well because it serves as a strong default for greenfield products and enterprise systems alike. MySQL stays highly relevant because it is entrenched in mature application stacks and operates reliably in many web-scale environments. MongoDB is popular where schema flexibility and document modeling align with development workflows. Redis is common because many applications need a low-latency auxiliary data store even if their primary database is something else. (db-engines.com)
What the 2026 data really says is that the market has converged around specialization. PostgreSQL is the broadest general-purpose relational choice. MySQL is the conservative relational choice. MongoDB is the document-first application database. Redis is the high-speed transient and real-time system. These roles overlap, but they do not collapse into one another. This is why teams increasingly use more than one database, but still anchor the architecture on a single primary system.
A useful interpretation of the trend data is this: the market has not “picked a winner” because the workloads are too different. Instead, each leading database has become a default for a different category of problem. That is good news for engineering teams, because it means you can optimize for fit rather than ideology. The challenge is resisting the temptation to choose by brand familiarity alone.
3. PostgreSQL deep dive: strengths, latest releases, and where it fits best
PostgreSQL remains the most compelling all-around database for teams that want one primary system to do many jobs well. Its biggest strength is that it combines relational rigor with advanced capabilities: robust SQL support, strong indexing options, powerful constraints, JSON support, full-text search, extensions, and an ecosystem that keeps growing without losing compatibility. If your application has transactional data, reporting needs, and a moderate amount of semi-structured data, PostgreSQL is often the best default.
Its release cadence also reinforces confidence. As of May 14, 2026, PostgreSQL 18.4 is available, alongside security and maintenance releases for 17.10, 16.14, 15.18, and 14.23. That matters because it shows the project is not only active but being maintained across multiple supported branches in a disciplined way. For production teams, that translates into predictability, patchability, and a healthy upgrade path. (postgresql.org)
Where PostgreSQL shines most is in systems that need correctness and flexibility at the same time. SaaS platforms, internal business applications, marketplaces, fintech workflows, and analytics-adjacent backends all benefit from its feature set. JSONB can model semi-structured entities without abandoning relational integrity. Window functions and advanced SQL make reporting easier. Extensions such as PostGIS and vector-related tooling expand its reach into geospatial and AI-adjacent workloads.
The tradeoff is that PostgreSQL’s breadth can tempt teams to use it for everything, including workloads better served by specialized systems. It can absolutely handle many workloads well, but that does not mean it is always the cheapest or fastest option for every niche. If your dominant need is ultra-simple key-value access, ephemeral state, or highly optimized cache reads, Redis may be a better companion. If your app is deeply document-centric and your team prefers object-like modeling, MongoDB can feel more natural. Still, as a primary system of record, PostgreSQL is the most balanced choice for most modern teams.
4. MySQL deep dive: LTS stability, ecosystem maturity, and ideal workloads
MySQL continues to earn its place in 2026 because it is boring in the best possible way. It is stable, well understood, widely hosted, and supported by a deep ecosystem of tooling, managed services, and operational knowledge. The MySQL 8.4 line is explicitly presented as an LTS track, and Oracle’s documentation distinguishes LTS from Innovation releases to help teams choose between long-term stability and faster feature adoption. That gives organizations a clear upgrade philosophy rather than a vague “latest version” mindset. (dev.mysql.com)
This matters because many production teams do not want surprise behavioral changes. They want a database that behaves consistently across years, not months. MySQL 8.4 LTS is attractive for organizations that prioritize operational predictability, long support windows, and minimal regression risk. The release notes also show active maintenance through 2026, including 8.4.8 in January and 8.4.9 in April, indicating a healthy patch stream. (dev.mysql.com)
MySQL is especially strong in classic OLTP workloads: content platforms, ecommerce backends, SaaS products with conventional relational schemas, and applications with high read volume and straightforward transactional patterns. It remains a very sensible choice when your team already knows MySQL deeply or when your hosting environment and tooling are already optimized around it. For many teams, that operational familiarity outweighs theoretical advantages of other databases.
The main downside is that MySQL’s developer experience is often less expressive than PostgreSQL’s for advanced querying and richer data types. If your application depends on sophisticated SQL, extensive use of JSON as a first-class data model, or advanced indexing and extension behavior, PostgreSQL is often a better fit. Still, if the goal is a dependable relational workhorse with a mature ecosystem, MySQL remains one of the safest answers in 2026.
5. MongoDB deep dive: document data, developer speed, and modern use cases
MongoDB remains the strongest option when your application naturally centers on documents instead of rows. That includes products where objects are nested, schemas evolve quickly, and different records may have different shapes. For frontend-driven development and rapidly iterating product teams, MongoDB can reduce friction because it maps more directly to application data structures. You spend less time normalizing early and more time shipping features.
In 2026, MongoDB is also clearly positioning itself around modern AI and operational data use cases. MongoDB’s 2026 announcements emphasize a unified data platform with a real-time database, search, vector capabilities, persistent memory, embeddings, and reranker models, aimed at production AI workloads. That direction matters because it shows MongoDB is no longer marketing itself only as a flexible document store; it is also trying to be a broader application data foundation. (mongodb.com)
For the right workload, MongoDB can be extremely productive. Product catalogs, user profiles, content management systems, event-driven applications, and fast-moving startups often benefit from its schema flexibility. Teams can evolve the data model without complex migrations on every iteration. Aggregation pipelines provide substantial query power, and the document model works well when nested JSON is the natural shape of the domain.
However, MongoDB’s strengths can become liabilities if used as a substitute for disciplined data modeling. Flexible schema does not mean schema-free design is free. You still need governance, validation, indexing strategy, and careful thinking about query patterns. For workloads where relational integrity, complex joins, and strong transactional semantics are central, PostgreSQL or MySQL is usually the better primary store. MongoDB is best when document shape and iteration speed are real advantages, not just preferences.

6. Redis deep dive: caching, sessions, queues, and real-time performance
Redis is not usually the primary database for durable business records, and that is precisely why it is so valuable. It excels where speed, simplicity, and ephemeral state matter. In practice, Redis is often the difference between a sluggish architecture and one that feels instantaneous. Its canonical uses include caching, session storage, rate limiting, distributed locks, queues, feature flags, leaderboards, and real-time counters.
The 2026 Redis roadmap shows how the project has broadened beyond the classic cache role. Redis has been emphasizing real-time and AI-oriented workloads, including semantic caching, agentic memory, and vector-related capabilities. Recent 2026 releases such as Redis 8.6 and 8.8 highlight performance improvements, streams enhancements, new eviction policies, and even new data structures. That trajectory reinforces Redis’s position as a fast-moving real-time data layer rather than a static utility. (redis.io)
Where Redis fits best is in architecture layers that need ultra-low latency and short-lived or derivable data. Authentication sessions, API response caches, background job coordination, live analytics counters, and ephemeral state for chat or gaming features are classic examples. If a value can be recreated from the source of truth or if losing it is acceptable, Redis is an excellent fit. Its data structures make many common tasks simple and fast.
The key caution is not to misuse Redis as a general system of record. It can persist data, but persistence is usually not the main reason to choose it. If you need durable relational transactions, complex queryability, or long-term records, put those in PostgreSQL or MySQL. Redis is best treated as a performance layer, a coordination layer, or a specialized memory layer that complements a durable database.
7. When something else is better: SQLite, CockroachDB, MariaDB, DynamoDB, and cloud-native options
There are many cases where none of the four headline databases is the best answer. SQLite is still excellent for local-first apps, embedded applications, mobile tooling, test environments, small desktop products, and single-node deployments. Its simplicity, portability, and zero-ops characteristics make it hard to beat when concurrency needs are modest and deployment complexity should be near zero.
CockroachDB is worth considering when distributed SQL is the core requirement. If you need transactional semantics across nodes, fault tolerance, and scaling without managing a traditional single primary database pattern, it may fit better than a manually sharded relational system. The tradeoff is additional architectural complexity and a narrower set of “normal” operating assumptions than PostgreSQL or MySQL.
MariaDB remains relevant for teams already invested in its ecosystem or needing compatibility with existing MySQL-oriented applications, but it is usually a compatibility or continuity choice rather than the leading new-build default. DynamoDB and other cloud-native key-value or document services are compelling when you want managed scaling, low operational overhead, and a design that fits access-pattern-driven workloads. They are especially attractive for teams that value elasticity over SQL flexibility.
The general rule is simple: use the specialized tool when the deployment model or workload shape justifies it. SQLite wins when simplicity wins. CockroachDB wins when distributed SQL is non-negotiable. MariaDB wins when ecosystem continuity matters. DynamoDB wins when managed scale and access-pattern design are more important than relational querying. The important thing is to resist forced standardization. A good architecture is not the one with the fewest database names; it is the one with the fewest accidental constraints.
8. Decision framework: choose by data model, consistency, scale, team skills, and budget
A practical database decision framework starts with the data model. If your core entities are strongly relational, with foreign keys, joins, and transactional workflows, pick PostgreSQL or MySQL. If your objects are naturally nested and vary significantly across records, MongoDB may be a better fit. If your data is transient, computationally derived, or performance-sensitive, Redis is the right auxiliary layer.
Next, evaluate consistency requirements. If correctness is critical—payments, inventory, subscriptions, account balances, and audit trails—use a database with strong transactional guarantees as the source of truth. PostgreSQL is often the best balance of flexibility and correctness. MySQL is also strong here, especially when you want a mature and conservative operational profile. MongoDB can absolutely support transactions, but the question is whether your broader model benefits enough from document structure to justify the tradeoff.
Then think about scale and access patterns. Many teams overestimate how much scale they actually need in the first two years. A well-designed PostgreSQL or MySQL system can handle very serious traffic. Redis can absorb hot-path reads and transient operations. MongoDB can simplify high-change product development. The real question is not “which database scales the most?” but “which database scales most cleanly for our dominant workload?”
Team skills are often underestimated. If your team already knows SQL well, PostgreSQL or MySQL will usually deliver faster and safer outcomes than switching to a document-first model. If your developers think in JSON and API resources, MongoDB may reduce friction. If your operations team is small, managed offerings and familiar tooling may matter more than feature checklists. Finally, budget must include not just licensing but labor, tuning time, migration cost, and on-call burden.
A useful mental model is to optimize in this order: correctness first, then developer velocity, then operational simplicity, then cost. If a database improves one dimension while harming two others, it is probably not the right choice.
9. Common architecture patterns: using multiple databases together without overcomplicating the stack
Most mature systems do not use one database for everything, but the best multi-database architectures remain simple. The pattern to aim for is “one system of record, one or two specialized companions,” not “database sprawl.” In practice, this often means PostgreSQL or MySQL as the primary durable store, Redis for caching and ephemeral state, and MongoDB or search/vector systems only when the domain truly benefits.
A very common pattern is PostgreSQL plus Redis. PostgreSQL stores authoritative business data, while Redis handles sessions, caching, rate limiting, queues, and low-latency derived state. This combination is popular because it keeps the core architecture understandable. You can scale read traffic, reduce latency, and keep transactional correctness in one place. For many SaaS and product companies, this is the sweet spot.
Another common pattern is MySQL plus Redis. This is especially attractive for teams with existing MySQL expertise or infrastructure. MySQL remains the source of truth, while Redis smooths hot paths and transient operations. This architecture is pragmatic and well-trodden, particularly in traditional web applications.
MongoDB plus Redis can also make sense for document-heavy products. MongoDB handles the flexible core model, while Redis accelerates session or cache workloads. This can be effective for content platforms, rapidly evolving product data, or AI-adjacent applications with changing object shapes. The important caveat is to avoid using MongoDB as a dumping ground for everything and Redis as a semi-durable store unless the tradeoffs are explicit and accepted.
The main anti-pattern is introducing a second database because it sounds modern. Every database adds complexity in schema ownership, backups, monitoring, access control, migrations, and incident response. Use multi-database designs when each database has a clearly bounded role. If two databases do the same job, you probably have an architecture problem, not a feature gap.
10. Final recommendations: database picks by startup, SaaS, analytics, e-commerce, and real-time apps
For startups, PostgreSQL is usually the best default. It offers the strongest balance of flexibility, correctness, and future growth. If the product is highly document-centric or the team strongly prefers schema-on-read development, MongoDB can be a reasonable alternative. But if you want one system that is hard to outgrow, PostgreSQL is the safest starting point.
For SaaS products, PostgreSQL is again the most common winner, especially for subscription logic, user management, billing data, and reporting-friendly schemas. MySQL is a strong alternative if your team already runs on it or if your deployment environment is built around MySQL conventions. Add Redis early if you have login sessions, background jobs, or read-heavy endpoints that need protection from hot-path traffic.
For analytics-heavy applications, none of these four databases is a complete warehouse replacement. Still, PostgreSQL can handle operational analytics and moderate reporting well, especially when paired with replicas or downstream analytics tooling. If your application is more document-centric, MongoDB aggregation may help with operational reporting. In either case, do not confuse operational databases with analytical warehouses.
For e-commerce, PostgreSQL and MySQL are the leading choices. Both handle inventory, orders, customers, and payments well. PostgreSQL is often preferable when the schema is richer or reporting needs are more complex. MySQL is excellent when the stack values stability and a very mature ecosystem. Redis should almost certainly be part of the architecture for carts, sessions, and caching.
For real-time apps—gaming, chat, collaboration, live dashboards, agent systems, or high-frequency interaction layers—Redis becomes essential as a companion database. PostgreSQL or MongoDB may still hold the authoritative state, but Redis is the layer that makes the system feel immediate. MongoDB can also be attractive when the data is document-shaped and fast-moving. For ultra-low-latency state, Redis is usually non-negotiable.
Conclusion
In 2026, the right database choice is less about ideology and more about fit. PostgreSQL is the best general-purpose default for most teams. MySQL remains the best bet for conservative, mature, relational workloads with a strong stability bias. MongoDB is the right choice when document structure and development speed are central to the product. Redis is the performance layer that almost every serious application benefits from, even if it is not the primary store.
If you need one guiding principle, use this: choose the smallest database stack that can satisfy correctness, development speed, and scale without creating unnecessary complexity. For many teams, that means PostgreSQL plus Redis. For some, it means MySQL plus Redis. For document-heavy products, MongoDB plus Redis can be the right combination. And for specialized workloads, alternatives like SQLite, CockroachDB, DynamoDB, or MariaDB can be the better strategic choice.
The best database in 2026 is not the most fashionable one. It is the one that aligns with your data model, your operational reality, and the next three years of product growth.