
Simple Background Job Worker in Node.js: Build a Reliable Queue in 2026
Modern Node.js applications often look fast on the surface while quietly accumulating expensive work behind the scenes: sending emails, processing images, syncing webhooks, generating reports, calling external APIs, and running AI-assisted pipelines. If you do all of that inside the request path, you eventually hit the same wall every time: slow responses, timeouts, duplicated work, and poor user experience.
A background job worker solves that problem by separating job submission from job execution. Instead of making a user wait while your app resizes an image or retries a payment capture, your API pushes a job into a queue and immediately returns a response. A worker process then picks up the job, executes it asynchronously, and stores the result or failure state for later inspection.
In 2026, the simplest reliable setup for Node.js background jobs is still a queue-backed architecture using Redis and a dedicated worker process. The ecosystem has matured, and for many applications, BullMQ plus Redis plus node-redis remains a practical stack: lightweight enough for small teams, but feature-rich enough for retries, delayed execution, concurrency, and observability.
This post walks through the core architecture, a modern stack choice, implementation details, reliability patterns, scaling concerns, operational visibility, and production guidance. The goal is not just to “make jobs run,” but to build a worker system that behaves predictably under load and failure.
1. What a Background Job Worker Is and Why Node.js Apps Need One
A background job worker is a separate execution unit that processes tasks outside the normal request/response lifecycle. In practice, that means your web server accepts a request, validates it, and enqueues a job. The worker consumes the job later, often in a different process, container, or host. This is especially useful in Node.js because the runtime is single-threaded at the JavaScript execution layer, so long-running CPU work or slow I/O can degrade latency for all requests sharing the event loop.
The main reason Node.js apps need background workers is to protect user-facing responsiveness. If an endpoint must wait on an SMTP server, a third-party API, an image library, or a model inference call, the request time can become unpredictable. Background jobs move that uncertainty out of the critical path. The API can respond in milliseconds with a job ID, while the worker handles the slower work in the background.
Workers also improve reliability. They can retry failed jobs, apply backoff, pause during outages, and isolate failures from the rest of your application. If a webhook delivery fails because a remote service is down, the worker can retry later without blocking the entire system. If a batch email send partially fails, the job can record progress and resume or fail cleanly. This creates a better operational model than scattered setTimeout calls or ad hoc cron scripts embedded in the web server.
There is another subtle benefit: background processing creates a clean boundary between product logic and operational side effects. Your API handles business intent, while the worker handles execution. That separation makes code easier to test, scale, and debug. It also helps with compliance and auditing, because job metadata, retry history, and completion states can be stored and inspected centrally. In larger systems, this becomes essential for async workflows such as order fulfillment, document generation, and AI orchestration.
2. Core Architecture: Queue, Producer, Worker, and Redis-Backed Storage
A simple job system is built from four core pieces: the producer, the queue, the worker, and the persistent backing store. The producer is usually your API or service code that creates jobs. The queue is the durable buffer that holds pending work. The worker is the process that pulls jobs from the queue and executes them. Redis is commonly used as the storage and coordination layer because it is fast, widely supported, and suitable for short-lived job state.
The producer’s job is straightforward: validate input, create a job payload, and add it to the queue. In many systems, the payload includes an identifier, a job type, metadata, and any arguments required for execution. The producer should avoid doing the actual work. Its responsibility is to make the intent durable and return quickly.
The queue provides decoupling. It prevents spikes in request traffic from overwhelming downstream systems. It also provides scheduling features such as delayed execution, retries, and job prioritization. In a practical implementation, the queue stores job metadata, status, timestamps, and retry information. Jobs may move through states like waiting, active, completed, failed, delayed, or stalled.
The worker is where the actual business logic runs. It pulls jobs from the queue, executes them, and records the outcome. A worker may run in the same codebase as the API, but it should generally be a separate process so it can scale independently and avoid tying up web server resources. For I/O-heavy tasks, multiple worker instances can run safely as long as they coordinate through the queue. For CPU-heavy tasks, the worker may need process isolation or offloading to another compute model to keep throughput stable.
Redis is the coordination backbone in this setup. It stores the queue state and enables atomic operations for claiming jobs and updating progress. That makes it a strong fit for short-to-medium duration jobs where speed and simplicity matter more than long-term durable workflow orchestration. For most Node.js applications, this gives an excellent balance of reliability and operational simplicity without introducing a heavyweight workflow engine.
3. Recommended Modern Stack: BullMQ, Redis, and node-redis for a Simple Worker Setup
For a clean 2026-friendly implementation, BullMQ is a strong choice for the queue layer, Redis is the persistence and coordination store, and node-redis is the official low-level Redis client for connecting your app to Redis. This combination keeps the system understandable while providing enough features for production use.
BullMQ is attractive because it provides job queues, delayed jobs, retries, concurrency, repeatable jobs, progress updates, rate limiting, and event hooks. It is designed for Node.js and fits naturally into asynchronous application code. Compared with hand-rolled queue logic, BullMQ eliminates a huge amount of subtle failure handling around atomic job claiming, retries, and state transitions.
Redis remains the operational core because BullMQ depends on it for queue state. The key practical requirement is that Redis must be stable, monitored, and sized appropriately. For production environments, that often means managed Redis or a durable self-hosted deployment with persistence, backups, and memory controls. If Redis disappears, the queue disappears, so the infrastructure around Redis deserves as much attention as the code using it.
The node-redis client is a sensible modern choice when you need direct Redis access for health checks, custom metadata, or auxiliary state. In a well-structured worker system, BullMQ handles the queue mechanics while node-redis can handle supporting concerns such as cache lookups, idempotency markers, or custom operational dashboards. This separation is useful because it avoids mixing low-level Redis calls into queue processing logic unless you actually need them.
The biggest advantage of this stack is clarity. You can explain the architecture in one sentence: API processes create jobs in BullMQ, Redis stores the queue state, and dedicated workers consume and process jobs. That clarity matters in production because it simplifies debugging, scaling, on-call rotation, and onboarding. If your team later needs to move to a more complex workflow engine, the conceptual model still translates well.
4. Step-by-Step Implementation: Enqueue Jobs, Process Jobs, Handle Async Work, and Return Results
A practical worker setup starts with a small queue abstraction and a dedicated worker entry point. The producer side adds jobs, and the worker side defines what those jobs mean. The important rule is to keep the payload small, stable, and serializable. Pass references, IDs, and small input data; avoid shipping huge blobs unless absolutely necessary.
Here is a minimal example of queue setup and job enqueueing:
// queue.js
import { Queue } from 'bullmq';
export const emailQueue = new Queue('emails', {
connection: {
host: process.env.REDIS_HOST,
port: Number(process.env.REDIS_PORT),
},
});// producer.js
import { emailQueue } from './queue.js';
export async function sendWelcomeEmail(userId, email) {
const job = await emailQueue.add('welcome-email', {
userId,
email,
}, {
attempts: 5,
backoff: {
type: 'exponential',
delay: 2000,
},
removeOnComplete: true,
});
return { jobId: job.id };
}The producer validates and submits a job, then returns a job ID that can be used for tracking. The worker consumes that job and performs the async work:
// worker.js
import { Worker } from 'bullmq';
const worker = new Worker(
'emails',
async job => {
const { userId, email } = job.data;
await job.updateProgress(25);
// simulate lookup or preparation
await new Promise(resolve => setTimeout(resolve, 250));
await job.updateProgress(60);
// simulate sending email
await new Promise(resolve => setTimeout(resolve, 500));
return {
delivered: true,
userId,
email,
sentAt: new Date().toISOString(),
};
},
{
connection: {
host: process.env.REDIS_HOST,
port: Number(process.env.REDIS_PORT),
},
concurrency: 5,
}
);
worker.on('completed', (job, result) => {
console.log(`Job ${job.id} completed`, result);
});
worker.on('failed', (job, err) => {
console.error(`Job ${job?.id} failed`, err);
});The job processor can return a result object, which is useful when the caller later wants to inspect final state or when another system consumes the completed output. For example, a report generation job might return a file path or object key, while an image job might return dimensions or storage URLs.
When handling async work, prefer explicit steps and clear error boundaries. If the worker needs to call external services, wrap each call in a timeout and meaningful error mapping. Do not let a job hang forever because a remote API stopped responding. Also, keep in mind that job payloads should reference durable source data rather than duplicating everything in the queue. If the user record or order record changes, the worker can fetch the latest state from the database when it runs.
A good implementation pattern is: enqueue with an ID, validate again in the worker, load full context from the system of record, process the task, persist results, and emit completion metadata. That design is resilient and easier to evolve than trying to pass every possible detail through the job payload.
5. Reliability Patterns: Retries, Backoff, Delayed Jobs, Dead-Letter Handling, and Idempotency
Reliability is where background workers either become genuinely useful or become a source of mystery and duplicate side effects. The queue needs to handle failures in a controlled way. Retries are the first line of defense. If a remote API is unavailable or a transient network issue occurs, retrying the job is often the right response. BullMQ supports multiple attempts, which lets you configure a job to try several times before marking it failed.
Backoff is equally important. Instant retries can make outages worse by hammering already overloaded systems. Exponential backoff spreads retries over time and increases the chance that the failure is transient rather than structural. For example, a job can retry after 2 seconds, then 4, then 8, then 16. This protects both your downstream services and your own queue from retry storms.
Delayed jobs are useful for time-based workflows. You might schedule an email reminder for tomorrow, a payment follow-up in one hour, or a cleanup task for after a grace period. Instead of relying on an external scheduler for every case, the queue can manage delayed execution directly. This reduces integration complexity and keeps job state centralized.
Dead-letter handling is the next layer. When a job exhausts its retries, it should not disappear silently. It should move into a failed state where it can be inspected, replayed, or manually remediated. In more advanced systems, failed jobs are copied or rerouted to a dead-letter queue for later analysis. That is especially useful when the failure mode is data-related rather than transient. If a payload is malformed or a business rule is violated, retries will not help, so the job should be quarantined and reviewed.
Idempotency is essential. A background job may run more than once because of retries, worker restarts, or network interruptions after side effects have occurred. That means the handler must be safe to execute multiple times without creating duplicate charges, duplicate emails, or duplicate records. The most reliable strategy is to use a unique idempotency key tied to the business operation and store the fact that the action already happened. Before performing the side effect, check whether the key has been processed. If it has, return success without repeating the work.
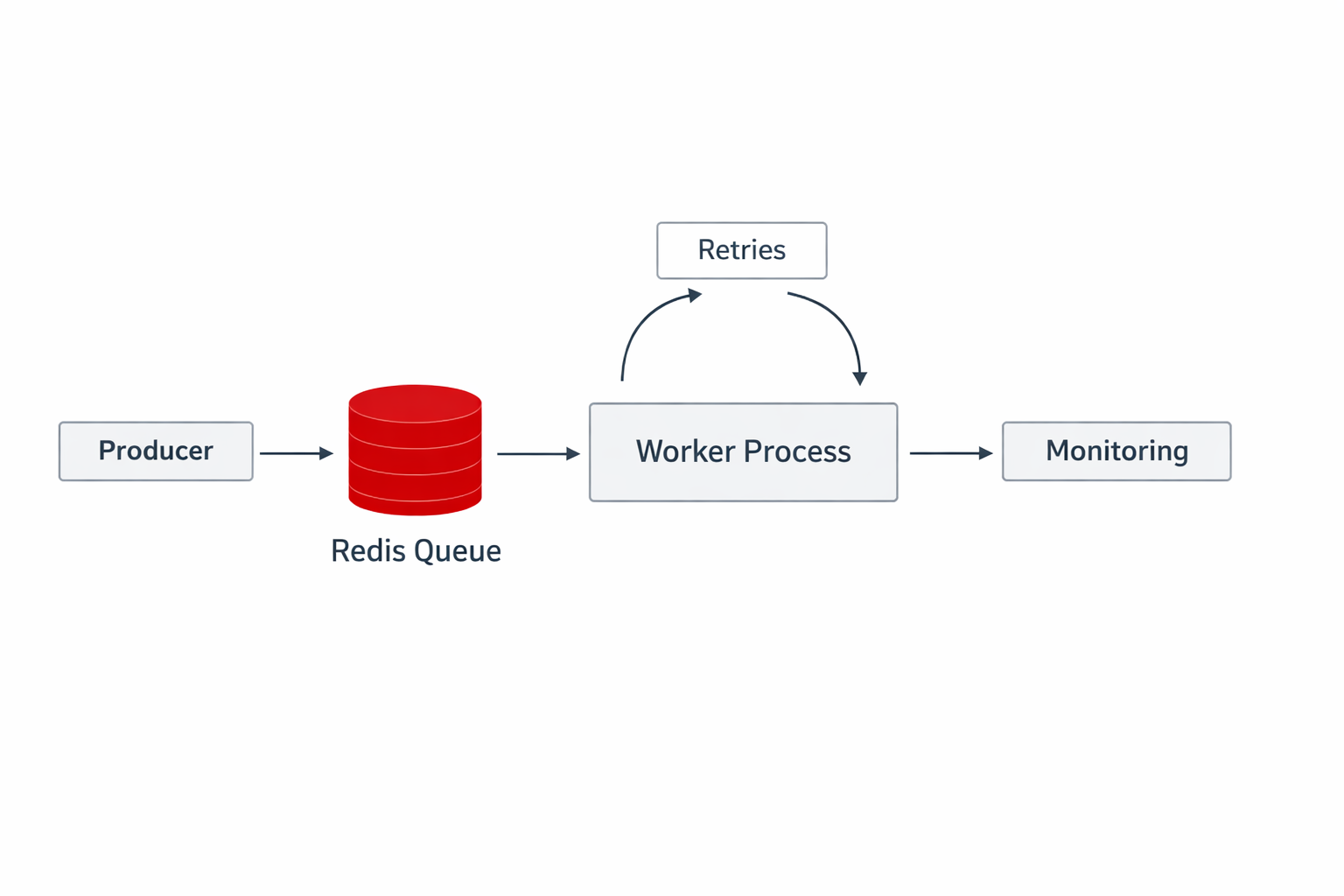
Taken together, retries, backoff, delayed execution, dead-letter handling, and idempotency create a worker system that behaves well in real conditions, not just in demos. That is the difference between a queue that looks good in development and a queue that survives production traffic.
6. Scaling and Performance: Concurrency, Horizontal Workers, Process Isolation, and Throughput Considerations
Once the basics work, the next challenge is throughput. Background systems tend to grow slowly and then suddenly become critical. The scaling model should be simple enough to reason about under load. In Node.js, the primary scaling lever for queue workers is concurrency. If jobs are mostly I/O-bound, a single worker process can handle multiple jobs at once by processing them concurrently. That works well when most of the time is spent waiting on network, database, or storage operations.
However, concurrency is not free. Higher concurrency increases memory usage, pressure on downstream services, and the chance of noisy-neighbor behavior within the process. If each job opens multiple connections, loads large files, or holds significant state, a high concurrency setting can hurt more than it helps. Start conservatively, measure queue latency and processing time, then increase concurrency based on real throughput data.
Horizontal scaling is usually the next step. Instead of one large worker process, run many worker processes or containers with moderate concurrency. Because the queue coordinates access to jobs, workers can scale out without manual partitioning in most cases. This is a strong operational model: if job lag grows, add more workers; if lag shrinks, scale them down. The queue becomes a shared buffer that absorbs traffic variation.
Process isolation matters for CPU-intensive jobs. Node.js workers that perform heavy image manipulation, PDF generation, encryption, or inference-like workloads can monopolize the event loop. In those cases, a dedicated process model is safer than trying to handle everything in the same runtime as the API. Depending on workload shape, you may use separate worker containers, Worker Threads, or even a different language/runtime for the heavy part. The important point is to protect the main API path from CPU spikes.
Throughput is not just about raw job count per second. It is about stable tail latency, predictable retry behavior, and downstream service health. If your worker can process 500 jobs per minute but causes your database to spike, your real throughput is much lower. Design for the slowest downstream dependency, not the fastest benchmark. That means observing queue wait time, average processing duration, failure rates, and backpressure signals from APIs, databases, and storage systems.
7. Operational Visibility: Monitoring, Logging, Progress Updates, and Queue Health Checks
A queue without visibility is a black box. In production, you need to know what is waiting, what is running, what is failing, and whether the worker fleet is healthy. Good operational visibility starts with structured logging. Every job should log a correlation identifier, job type, queue name, attempt count, duration, and outcome. Avoid unstructured console noise. Logs should be searchable and consistent so that an on-call engineer can trace a single job across request logs and worker logs.
Progress updates are especially useful for longer jobs. If a job has multiple stages, the worker should publish progress percentages or milestones. This helps dashboards and APIs provide user feedback such as “uploading,” “processing,” and “finalizing.” It also makes stuck jobs easier to identify. When a job has not advanced in a long time, it may indicate a deadlock, external API issue, or resource exhaustion.
Monitoring should cover both queue metrics and process metrics. Queue metrics include wait time, active jobs, delayed jobs, failed jobs, completed jobs, retry counts, and age of the oldest pending job. Process metrics include CPU usage, memory growth, event loop delay, open handles, and restarts. A queue may look healthy at the queue level while the worker process is slowly exhausting memory. The opposite can also happen if Redis latency causes job pickup delays while the worker appears idle.
Health checks are mandatory for deployment automation. A worker health check can confirm that the process is alive and able to reach Redis. A deeper readiness check can verify that the worker can actually claim jobs and that Redis latency is within acceptable bounds. For systems with strict SLAs, you may also want an alert when queue lag exceeds a threshold or when failure rates spike.
In production, monitoring is not a luxury feature; it is part of the job system itself. Without it, retries become invisible, failures pile up, and operators only notice problems when users complain. With good observability, background jobs become a controlled subsystem instead of a guessing game.
8. Comparing Implementation Options: In-Process Jobs vs Worker Threads vs Dedicated Queue Workers
There are several ways to run background work in Node.js, and the right choice depends on reliability and workload shape. In-process jobs are the simplest. You call asynchronous logic from your API server and let it finish later, often with setImmediate, setTimeout, or internal promise chains. This is easy to write but fragile in practice. If the process restarts, the work disappears. If the server scales horizontally, each instance has its own isolated in-memory tasks. For anything important, in-process work is usually too weak.
Worker Threads are a better option when the task is CPU-heavy and you want to keep the main event loop responsive. They run code in separate threads within the same process boundary, which can help with parallel computation. That said, Worker Threads are not a full queue system. They do not solve persistence, retry policy, delayed jobs, or distributed coordination. They are excellent for computational offloading, but not sufficient as the primary job orchestration model for most applications.
Dedicated queue workers are the strongest general-purpose choice for production background tasks. They provide durability, decoupling, retries, and scaling across processes or machines. They are better for tasks that may take seconds or minutes, tasks that must survive process restarts, and tasks that benefit from operational visibility. The tradeoff is additional infrastructure and a more deliberate deployment model.

A useful rule of thumb is this: use in-process work only for non-critical convenience tasks, use Worker Threads for CPU hotspots inside a controlled service, and use dedicated queue workers for anything important, slow, retryable, or operationally sensitive. Most teams end up with a hybrid approach. For example, an API may enqueue a job, the worker may use Worker Threads for a heavy transformation step, and the final output may be saved to object storage. That combination gives you the best parts of each model without forcing one abstraction to do everything.
9. Common Use Cases: Emails, Webhooks, Image Processing, Payment Tasks, and AI/Background Pipelines
Background workers are useful anywhere work is important but not immediately required by the user request. Email delivery is one of the most common examples. Sending transactional email through a worker prevents a slow SMTP call from delaying a checkout or signup flow. It also gives you retries when a mail provider has temporary issues and a clean place to record delivery failures.
Webhook delivery is another strong fit. If your application needs to notify third-party systems, a worker can serialize outbound calls, manage retries, and track status per endpoint. That is much safer than firing webhooks directly from the request path, where a temporary timeout could produce inconsistent behavior. A queue also helps with rate limits, which matter a lot when multiple integrations are involved.
Image processing and file generation are classic worker tasks. Resizing uploads, generating thumbnails, converting formats, creating PDFs, and extracting metadata all benefit from asynchronous processing. The user can upload a file and receive an immediate response while the worker performs the transformation in the background. This improves user experience and isolates heavy storage or CPU operations from the API.
Payment-related tasks often belong in workers too, though with strong safeguards. You might capture a payment, reconcile a transaction, generate an invoice, or poll for settlement. Because payment systems are sensitive to duplicates and partial failure, these jobs must be idempotent and carefully logged. A queue helps manage retries, but your business logic must still prevent double charging or repeated side effects.
AI and background pipelines are increasingly common in 2026. Many applications now use asynchronous steps for embedding generation, document chunking, moderation, classification, retrieval preprocessing, or report synthesis. These tasks often involve multiple external calls and variable latency, which makes them a natural fit for workers. A queue can orchestrate pipeline stages, track progress, and isolate failures in one step without stopping the entire flow.
The best use cases share a common profile: the work is useful, slow, retryable, and not required for the immediate HTTP response. That is the sweet spot where background jobs deliver the most value.
10. Production Checklist and Conclusion: Security, Testing, Deployment, and Maintenance
Before shipping a background worker system to production, run through a disciplined checklist. Start with security. Job payloads may include user identifiers, file references, or tokens, so sanitize inputs carefully and avoid storing secrets in jobs. Ensure workers have least-privilege access to databases, object storage, and third-party APIs. If a worker only needs to send emails, it should not have broad access to unrelated services. Protect Redis with network controls, authentication, and proper deployment boundaries.
Testing is next. Unit test the job handler as a pure function where possible, and integration test the full queue path from producer to worker. Verify retry behavior, failure handling, and idempotency. Test what happens if Redis is unavailable, if a downstream API returns 500s, if the worker crashes mid-job, and if the same job is processed twice. Those are the cases that matter in production, not just the happy path.
Deployment strategy also matters. Workers should usually be deployed independently from the API, with separate scaling policies and restart behavior. If the API gets busier, you scale web pods; if queue lag grows, you scale workers. Keep configuration consistent across environments, and avoid mixing experimental queue settings into production without load testing. Add graceful shutdown so workers finish or requeue in-flight work when the process stops.
Maintenance is an ongoing responsibility. Monitor job age, queue backlog, failure spikes, Redis memory usage, and dead-letter volume. Periodically review retry policies and adjust backoff for real failure patterns. Archive or clean up completed jobs according to retention needs, and revisit idempotency keys when business workflows change. Background processing is not a one-time feature; it is an operational subsystem that evolves with your application.
The takeaway is simple: a reliable background job worker in Node.js is not about just “running code later.” It is about building a durable async execution model that protects your API, tolerates failures, scales predictably, and gives operators enough visibility to trust it. With BullMQ, Redis, and node-redis, you can build that system without unnecessary complexity. If you design for retries, idempotency, observability, and clear process boundaries from the start, your queue will remain a strength of your architecture instead of becoming a hidden source of incidents.